Web Scraping with Selenium IDE
How to extract data from a website
This page explains how to do web scraping with Selenium IDE commands. Web scraping works if the data is inside the HTML of a website. If you want to extract data from a PDF, image or video you need to use visual screen scraping instead.
How to generate a good XPath for web scraping
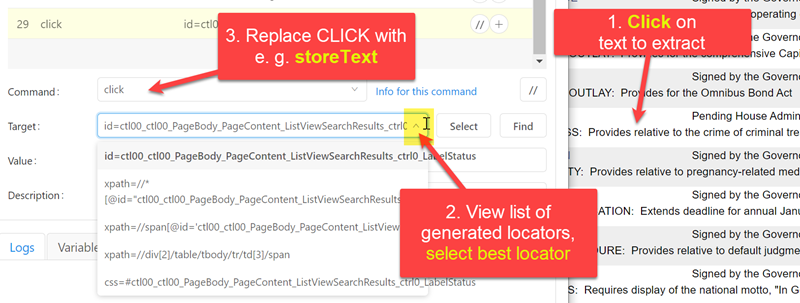
The easiest method is to first record a CLICK on the element that you want to extract. This works even if the element is not a link, but e. g.
a table entry. This generates a CLICK command a few suggested locators (XPath). Press the "Down" arrow in the IDE to see the full list of suggested, possible locators.
Once you have decided on a good locator, then simply change the CLICK command to e. g. STORETEXT or STOREATTRIBUTE:
When to use what command?
The table belows shows the best command for each type of data extraction. Click the recommended command for more information and example code.
| Data to extract is in... | Command to use | Comment |
|---|---|---|
| Visible website text, for example text in a table just like this one, or a price on website | storeText | |
| Text in input fields (input box, text area, select drop down,...) | storeValue | Do not confuse this command with storeEval, which is not for web scraping. |
| Get the status of a checkbox or radiobutton | storeChecked | |
| URL "behind" an image | storeAttribute@href | storeAttribute | xpath=...@href extracts the link of any element - if it has one! If that fails, consider browser automation to copy the link to the ${!clipboard} variable. |
| ALT text "behind" an image | storeAttribute@alt | The storeAttribute command can be used to get any attribute the HTML element has. For example, use @alt to get the "Alt" text of an image. |
| Page title | storeTitle | |
| Table content: Row/Column/Cell | storeText with XPath locator | See TABLE Web Scraping or automate browser addon |
| Data from a list e. g. search results | Loop over storeText | See How to web scrape search results |
| Save complete web page source code | XType | ${KEY_CTRL+KEY_S}* | On Mac it is ${KEY_CMD+KEY_S}. |
| Save complete web page with images | XType | ${KEY_CTLR+KEY_S}* | See Forum post: How to save the entire HTML code |
| Take screenshot of website | captureEntirePageScreenshot* | This saves the complete website as image. |
| Take screenshot of a web page element | storeImage* | The element can be an image or any other web page HTML tag |
| Download an image from a website | saveItem* | Retrieve the image directly from the browser cache. |
| Text found only website source code | sourceExtract* | e. g. Google Analytics ID. For text inside page comments or Javascript, this is the only option |
| Extract complete website HTML with | executeScript to get entire HTML code | Useful if you want to extract the complete HTML source code of the website, e. g. as input for aiPrompt |
| JSON data displayed in web browser | storeText | css=Pre | json | A web api (e. g. OCR Api) displays JSON in the browser, not HTML. storeText with locator "css=Pre" can be used to extract it (Example: JSON scraping RPA) |
| PDF, Image, Video, Canvas | OCRExtractRelative and OCRExtractByTextRelative | This screen scraping command works everywhere because it works visually. The disadvantage is that it is slower than the pure HTML-based commands like storeText. |
| Text from outside the web page | OCRExtractRelative and OCRExtractByTextRelative | If you run these commands in desktop mode you can read data from any desktop app. |
(*) These commands are only available in the Ui.Vision RPA Selenium IDE. They are not part of the classic Selenium IDE.
See also
- - Screen scraping (scraping/data extraction with computer vision, OCR)
- - Text parsing with AI and LLM
- - Form filling with Selenium IDE (the opposite of web scraping)
- - File uploads with Selenium IDE
- - Best Selenium IDE Locator Strategy
- - RPA Software User Manual.
Anything wrong or missing on this page? Suggestions?
...then please contact us.