Selenium IDE Locators
Different types of Selenium IDE Locators
Locator is a fancy word for how you tell Selenium IDE to find the right place to click on. We use here “click”, but the same applies for other commands that do something else with a DOM element. In other words, locators are used as input by all commands that do something at a specific place.
What is the difference between locator and selector? There is no difference! These are two words for the same. Typically when it comes to CSS, we start addressing the locators as CSS selectors. But CSS selectors are also locators.
Record and Replay: All Selenium IDE flavors have a record mode for web automation. During recording the RPA software uses internal logic to find the best possible locator. Often this works, but on more complex websites this can fail. Thus there are times when the automatically created locator does not work, for example when the element ID changes between page loads. In this case you need to tweak the locator manually or switch to using a visual locator, which is slower but (by design) always works . This page helps you with finding the best locator strategy.
-
Selenium IDE Locators for Browser Automation:
- 1. ID Locator
- 2. Name Locator
- 3. Link Locator
- 4. XPath Locator
- 5. CSS Locator
-
Visual Locators for Browser and Desktop Automation:
- 6. Image Locator
- 7. Text Locator (OCR)
Selenium IDE Locators
ID Locator
The ID locators looks for an element in the page having an id attribute.
Example: <label id="my_id" /> will be matched by a locator
like id=my_id.
-
PROS:
- 1. Very simple to use. Each id is unique so no chance of matching several elements.
- 1. Most elements do not have the ID attribute
- 2. Generated IDs often change between page load. Solution: Match changing ID
CONS:
Name Locator
Like the Id locator, but on the name attribute. PROs and CONs are the same.
Example: <button type="button" name="car" value="tesla"> will be matched by a locator like
name=car>.
Link Locator
This locator works with links only. It finds the link containing the specified text.
It comes in two flavors: linkText and partialLinkText.
Example: A link called "Click here to download" will be matched by a locator like
linkText=Click here to download
and partialLinkText=here to.
-
PROS:
- 1. Very simple to use.
- 2. If there is more than one link with the same name, use the POS attribute
-
CONS:
- 1. Obviously, works with link elements only
- 2. Fails when the link text changes between page loads
XPath Locator
XPath is the standard navigation tool for XML and an HTML document is also an XML document (xHTML).
Today XPath is used everywhere in web testing software.
Example: <button type="button" name="car" value="tesla"> will be matched by an XPath locator like
xpath=//button[@@value="tesla"].
-
PROS:
- 1. Allows very precise locators
- 2. XPath implementations are complete in Chrome, Firefox and Edge, so the XPath locator works well for cross-browser testing.
- 3. Advanced concepts such as //*[contains(.,‘Los Angeles’)] help to create stable locators. Example: Web scraping data from tables.
-
CONS:
- 1. For users not familiar with web development, XPath has a certain learning curve.
- 2. Some says that is slower than CSS, but this is neglible for Selenium IDE. So please ignore this. This is not an issue at all.
CSS Locator
The CSS locator strategy uses CSS selectors to find the elements in the page.
Example: <button type="button" name="car" value="tesla"> will be matched by the
CSS selector
css=button[value="tesla"]>.
-
PROS:
- 1. Allows very precise locators
- 2. Allows for selection of elements by their surrounding context
-
CONS:
- 1. They tend to be more complex and require a steeper learning curve
- 2. Works as well as XPath, but not better. So unless you are already familiar with CSS selectors, we recommend to use XPath locators instead (easier).
Visual GUI Locators
Visual locators are not available in the standard Selenium IDE, but only in RPA software. Visual locators are easy to use (no HTML knowledge required) and they work reliably even with the most complex web apps. The drawback is that they are slower, a visual command takes typically one to a few seconds for the computer vision to find the image or text.
Image Locator
This locator uses computer vision (image recognition) to find the right
place on the screen. Note that it does not find web elements, but "places". So it works the same
on website, Citrix, SAP, PDF documents or for general desktop automation.
This locator is supported by the XClick,
XMove,
and all GUI testing commands.
Example of using image recognition for automation
-
PROS:
- 1. Easy to use
- 2. Works for testing canvas elements
- 3. Works with desktop apps
-
CONS:
- 1. Replay speed is slower than classic Selenium locators
Text Locator (OCR)
The text locator uses computer vision (OCR) to find the right
place on the screen by searching for text. Note that it does not find web elements, but "places". So it works the same
on website, Citrix, SAP, PDF documents or for general desktop automation.
This locator is supported by the XClick and
XMove commands.
Example: See OCR Clicks
-
PROS:
- 1. Extremely easy to use
- 2. Works for testing canvas elements
- 3. Works with desktop apps
- 4. Since it uses OCR screen scraping, this locator is stable against resolution, color, font and even size changes.
-
CONS:
- 1. Replay speed is slower than classic Selenium locators
- 2. Obviously works with text only, but not with buttons and icons
What about the DOM and UI-element locators?
The DOM strategy works by locating elements that matches a certain javascript expression. The UI-elements locators (not to be confused with modern visual GUI locators!) is an even more complex way to describe elements using pagesets and regular expressions. These two locator types are not useful for working with Selenium IDE and can be safely ignored.
Appendix Selenium IDE locator strategy
Primary and Secondary Locators
In addition to the "first choice" (main) locator, the Ui.Vision Selenium IDE++ records alternative locators, also called primary and secondary locators. The IDE records and keeps all possible locators and uses them if the primary locator (as picked by the IDE) fails. This is a great way to save time during script development and find the best locator strategy. For example, it often finds a solution for dynamic IDs automatically. After the search for the primary locator times out, the IDE tries every secondary locator in the list, until one matches:
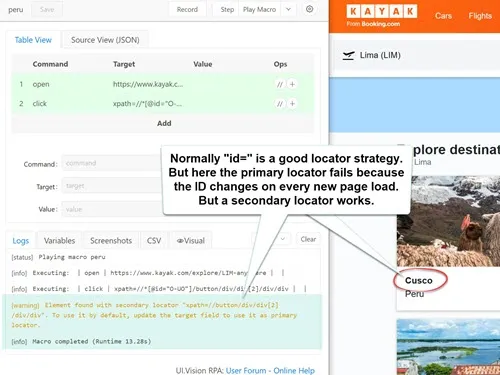 Here the primary locator failed because the element ID changed.
Here the primary locator failed because the element ID changed.
 But a secondary locator that does not use the ID locator strategy works.
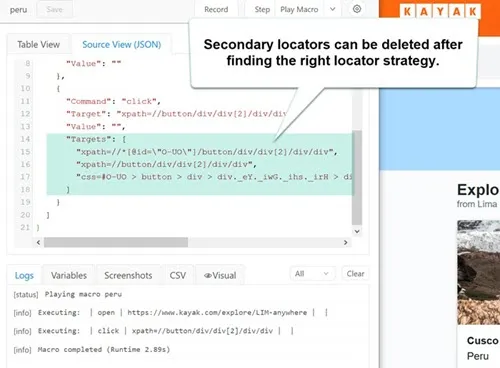
We make this secondary locator the main locator and can now safely delete
the list of secondary locators that are stored in the TARGETS value.
But a secondary locator that does not use the ID locator strategy works.
We make this secondary locator the main locator and can now safely delete
the list of secondary locators that are stored in the TARGETS value.
Related topics
Web Scraping with Selenium IDE
Anything wrong or missing on this page? Suggestions?
...then please contact us.
