sourceExtract, sourceSearch - Ui.Vision RPA Selenium IDE
Search and extract page source code with Selenium IDE command
The sourceSearch and sourceExtract commands work with the page source code instead of looking at the web page object model (DOM) that all other "classic" Selenium IDE command use. Thus sourceSearch/sourceExtract can verify e. g. comments in the page source code and can check/extract Javascript code parts (like the Google Analytics ID) that are invisible to a command like storetext.
Both commands can be used in a plain text mode. Then "*" wildcard indicates the changing part.
For experts, both commands support standard Regular Expressions (often called regex or regexp).
In sourceExtract, if no match is found, the variable is set to "#nomatchfound" - and no error is triggered.
You find examples of both commands in DemoExtract (sourceExtract) and DemoStoreEval (sourceSearch). Both macros get installed with Ui.Vision RPA.
sourceSearch supports the regex=/your pattern/i syntax. This can be used, for example, for case-insensitive text search.
Regex Capture Groups
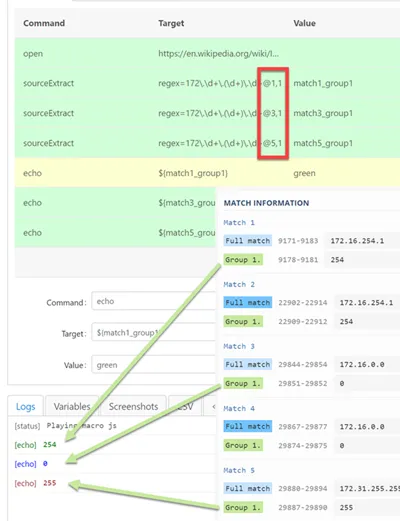
The notation to extract regex capture groups is regex=…@@MATCH,GROUP. See also: How do you use Regex capture groups and Quick guidance on regex please.
 Regex capture groups explained. The screenshot is from the regex forum post.
Regex capture groups explained. The screenshot is from the regex forum post.
sourceExtract Example
Some text here first. The following examples will operate on it.
- Coffee $2.95
- Tea $1.95
- Milk $2.10
Another test string: width: 11, width: 22, width: 33
| Command | Target | Result (stored in the variable) |
|---|---|---|
| sourceSearch | $*</li> | 3 (= 3 matches found) |
| sourceSearch | regex=[\$\£\€](\d+(?:\.\d{1,2})?) | 3 (= 3 matches found, same as before, but now with regular expressions) | sourceSearch | Tea $*</li> | 1 (= 1 match found) |
| sourceSearch | Beer $*</li> | 0 (no match found) |
| sourceExtract | $*</li> | $2.95</li> (the coffee, without @@ the first match (@@1) is assumed) |
| sourceExtract | $*</li>@@2 | $1.95</li> (the tea) |
| sourceExtract | $*</li>@@5 | #nomatchfound |
| sourceExtract | regex=[\$\£\€](\d+(?:\.\d{1,2})?)@@2 | 1.95 (the tea) |
| sourceExtract | regex=width: (\d+)@@2 | width: 22 |
| sourceExtract | regex=width: (\d+)@@2,1 | 22 (the 2,1 means the first capture group of the second match) |
Works in
Ui.Vision RPA for Chrome Selenium IDE
Related Demo Macros
ClickandWait is part of almost every demo macro-
The ready-to-import-and-run source code of all demo macros can be found in the Open-Source RPA software Github repository.
See also
clickAndWait, Web Automation Extension User Manual, Selenium IDE commands, Classic Firefox Selenium IDE.
Anything wrong or missing on this page? Suggestions?
...then please contact us.
